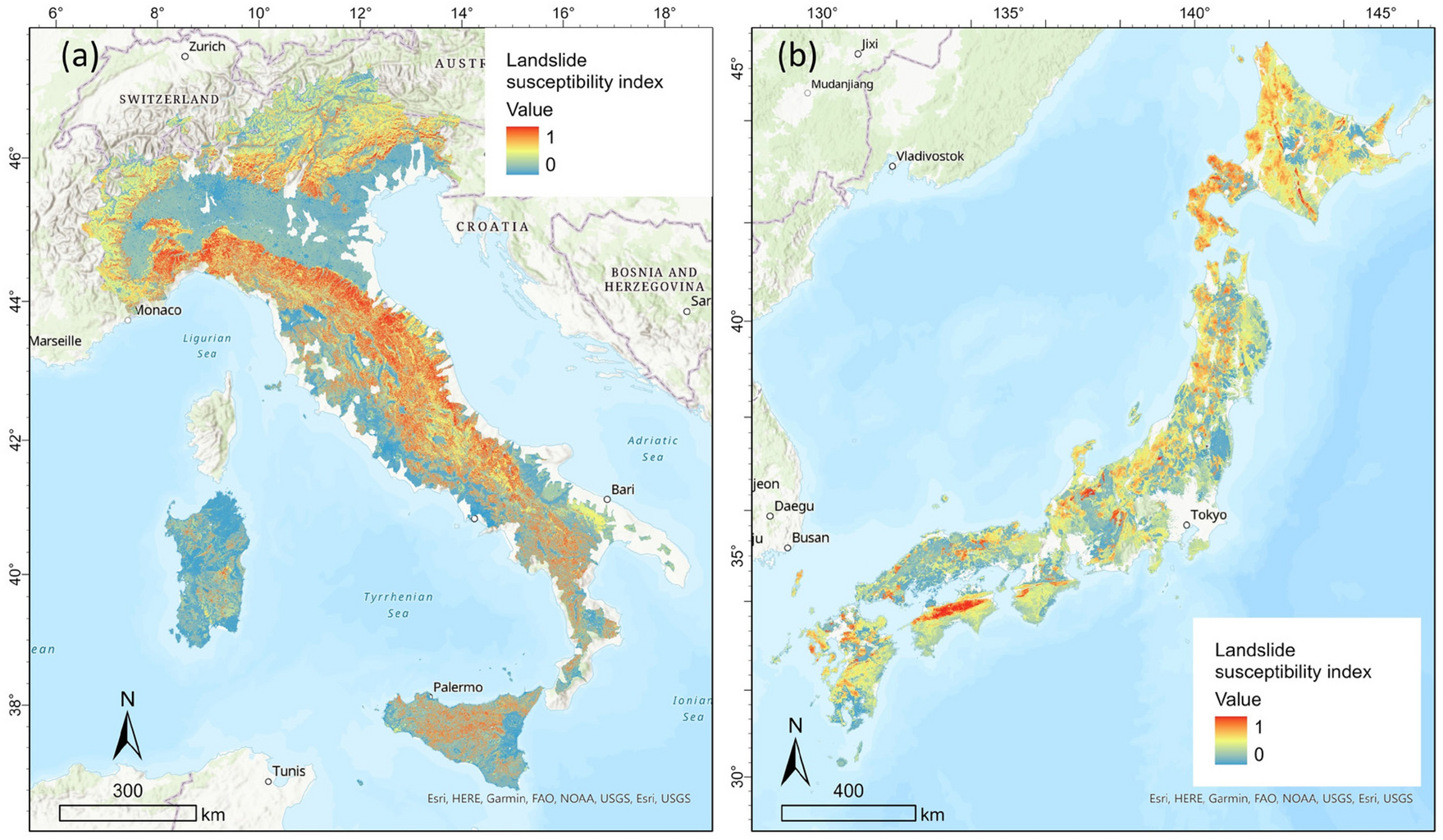
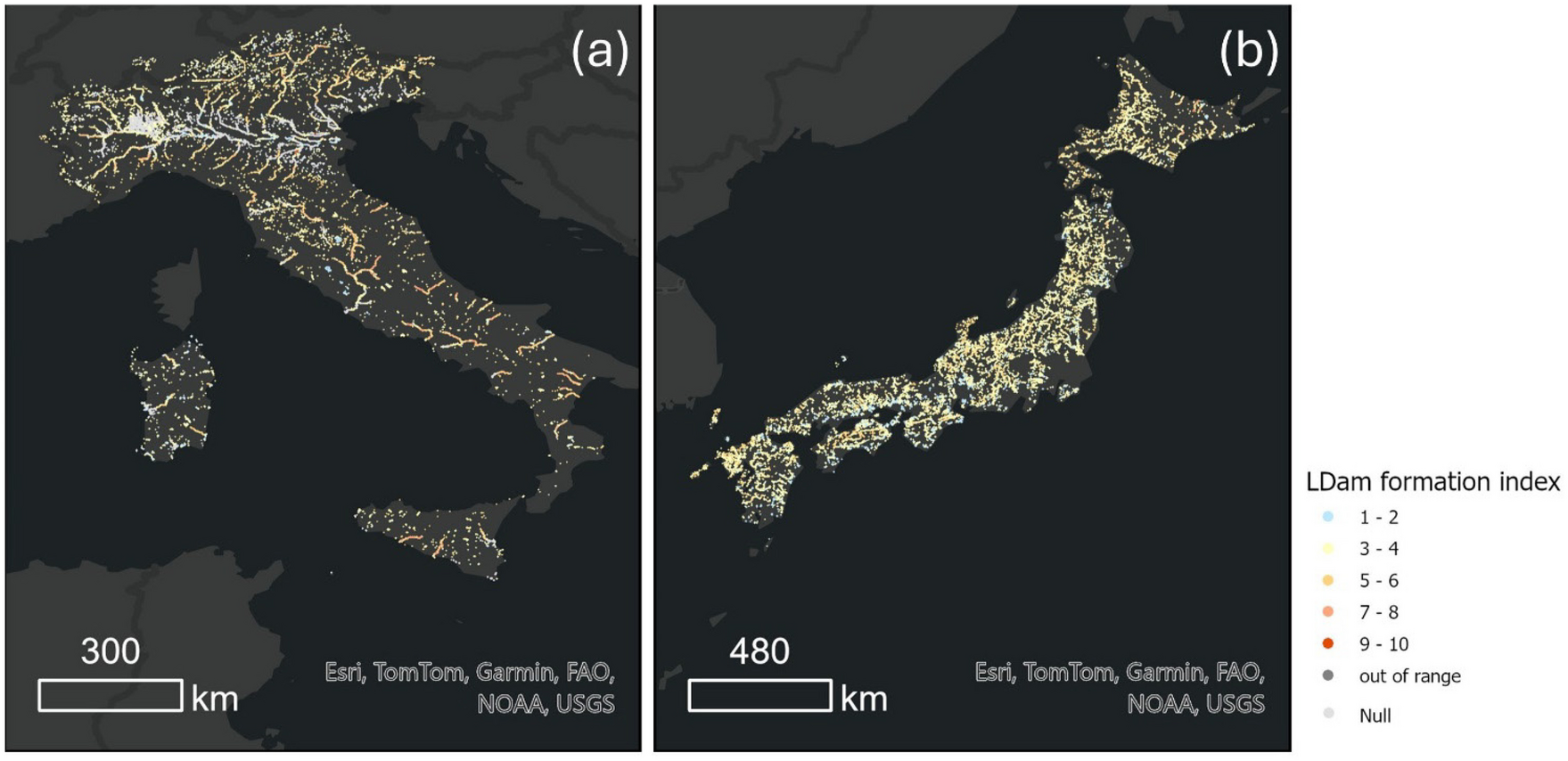
DAS(ヘテロダインOTDR)を理解するため、順に可視化してみました(Thanks! GPT)。
誤っていたらいずれ気づくでしょう。その際に修正しましょう。
まずは import。
import numpy as np
from scipy.signal import hilbert, butter, filtfilt
import matplotlib.pyplot as plt
レーザーを作成します。
# サンプリング周波数
fs = 5000 # サンプリング周波数
t = np.linspace(0, 1, fs, endpoint=False) # 1秒間の時間軸
# 信号の周波数
f_signal = 1000 # 1000Hzの振動信号
signal = np.sin(2 * np.pi * f_signal * t)
# 周波数シフト
carrier_freq = 1010
carrier_wave = np.sin(2 * np.pi * carrier_freq * t)
# 後方散乱光
# 光ファイバーから得られた2ショット
# 位相が少しずれている
scattered_signal1 = np.sin(2*np.pi*(carrier_freq)*t
+ 2*np.pi*0.1)
scattered_signal2 = np.sin(2*np.pi*(carrier_freq)*t
+ 2*np.pi*0.2)
plt.plot(t[:100],signal[:100],label="signal")
plt.plot(t[:100],carrier_wave[:100],label="carrier",c="green")
plt.plot(t[:100],scattered_signal1[:100],label="scatteres1")
plt.plot(t[:100],scattered_signal2[:100],label="scatteres2")
plt.legend()
戻ってきた光を干渉させます。
sin波の積和の公式より、高周波成分と低周波成分が生まれます。
# 干渉信号の生成
interfered_signal1 = scattered_signal1 * signal
interfered_signal2 = scattered_signal2 * signal
plt.plot(t[:100],interfered_signal1[:100])
plt.plot(t[:100],interfered_signal2[:100])
光の高周波数は検出できませんが、干渉後の低周波成分は検出可能です。
# Butterworthフィルタ(ローパス)
cutoff = 50
# 正規化周波数
Wn = cutoff / (f_signal / 2)
# Butterworthフィルタの設計
b, a = butter(4, Wn, 'low')
filtered_signal1 = filtfilt(b, a, interfered_signal1)
filtered_signal2 = filtfilt(b, a, interfered_signal2)
plt.plot(t,filtered_signal1)
plt.plot(t,filtered_signal2)
低周波側の信号から位相を取り出し、2ショット間の位相差を算出します。
ここはプロのノウハウがあるそうです。図書にも見当たらないので推定です。
# ヒルベルト変換を用いた瞬時位相の抽出
analytic_signal1 = hilbert(filtered_signal1)
instantaneous_phase1 = np.unwrap(np.angle(analytic_signal1))
analytic_signal2 = hilbert(filtered_signal2)
instantaneous_phase2 = np.unwrap(np.angle(analytic_signal2))
# 瞬時周波数の計算
instantaneous_frequency1 = np.diff(instantaneous_phase1)
/ (2.0 * np.pi) * fs
instantaneous_frequency2 = np.diff(instantaneous_phase2)
/ (2.0 * np.pi) * fs
plt.figure(figsize=(10, 10))
# プロット:位相
plt.subplot(311)
plt.plot(t, instantaneous_phase1)
plt.plot(t, instantaneous_phase2)
plt.title('Extracted Phase from Interfered Signal')
plt.xlabel('Time [s]')
plt.ylabel('Phase [radians]')
plt.grid(True)
plt.subplot(312)
plt.plot(t, instantaneous_phase2-instantaneous_phase1)
plt.title('Extracted Phase from Interfered Signal')
plt.xlabel('Time [s]')
plt.ylabel('Phase [radians]')
plt.grid(True)
# プロット:周波数
plt.subplot(313)
# t変数の長さをinstantaneous_frequencyに合わせる
plt.plot(t[:-1], instantaneous_frequency1)
plt.plot(t[:-1], instantaneous_frequency2)
plt.plot(t[:-1], instantaneous_frequency2
-instantaneous_frequency1)
plt.title('Instantaneous Frequency')
plt.xlabel('Time [s]')
plt.ylabel('Frequency [Hz]')
plt.ylim(-20,20)
plt.grid(True)
plt.tight_layout()