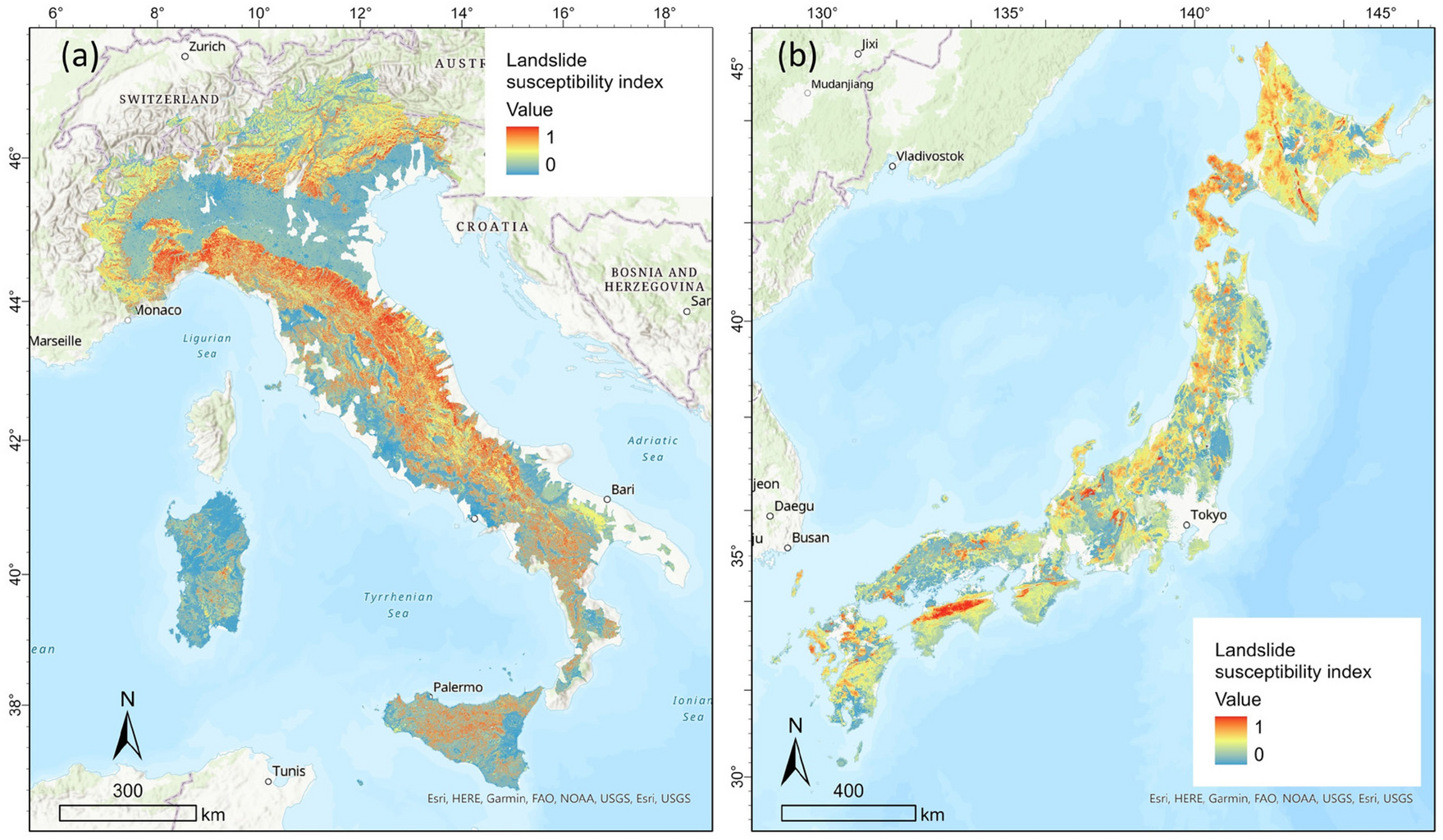
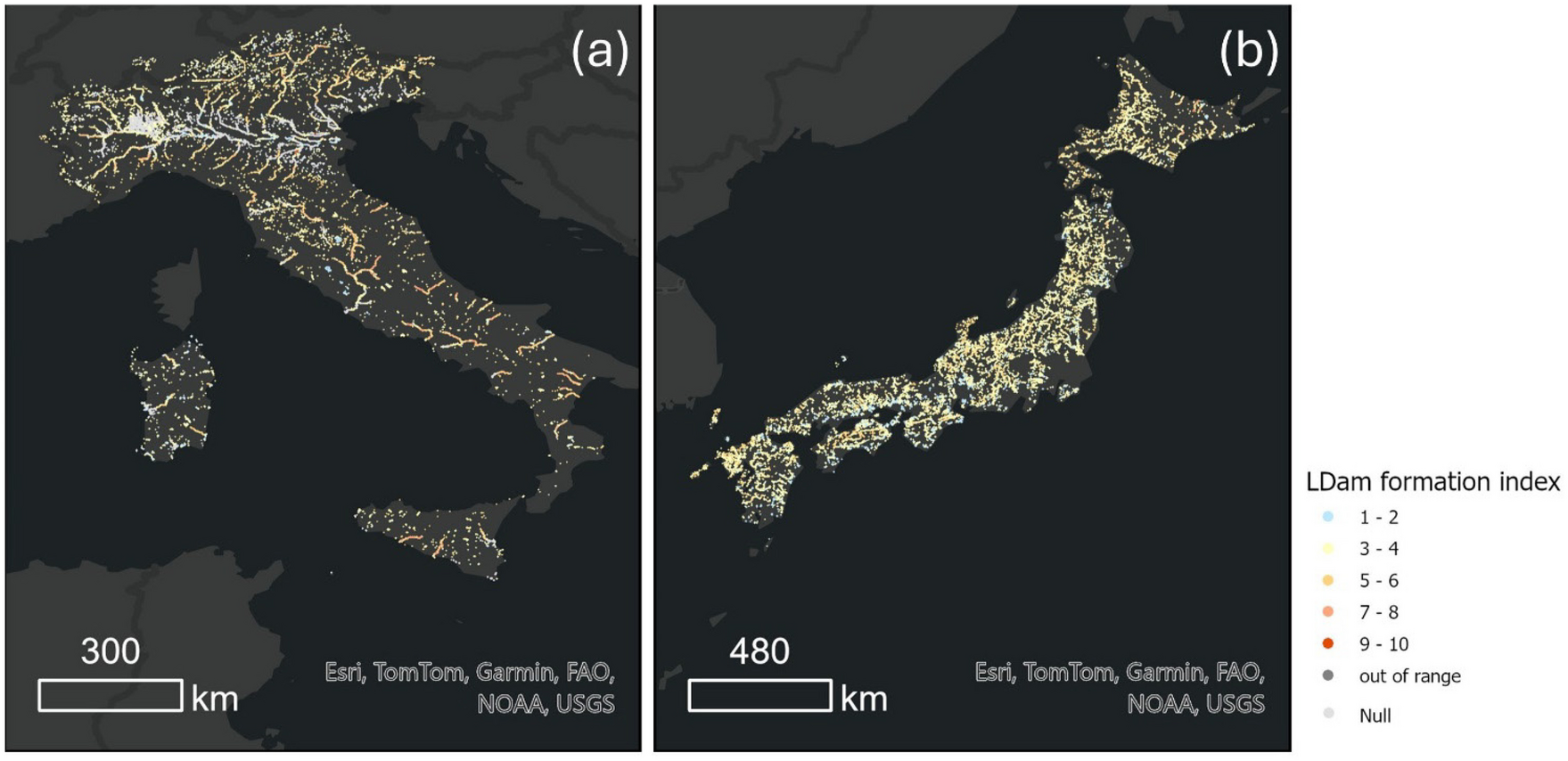
日本では、「Landslide Susceptibility Map」に対応する統一的な用語はまだ確立されていません(産総研さんは「感受性マップ」でした)。
土砂災害に関するマップは古くから作成されていますが、様々な表現が用いられています。「ハザードマップ」と「リスクマップ」についても、明確に区別されずに使用されています。
崩壊の危険度に関するマップとして、まずは深層崩壊。国交省から公開されていますが、ここでは隆起量や地質を考慮されているようです。豪雨時のハザードマップの材料として利用可能でしょう。
●深層崩壊推定頻度マップ
過去の発生事例から得られている情報をもとに深層崩壊の推定頻度に関する全国マップを作成しました。(2010/08)
●渓流レベル評価マップ
空中写真判読等による深層崩壊の渓流(小流域)レベルの調査。(2012/09)
https://www.mlit.go.jp/mizukokudo/sabo/deep_landslide.html
地震時の斜面崩壊に対するハザードマップもあります。
この六甲式は評価手法になるのですが、得られるのはマップです。シンプルな式ですが、経験的に良い性能を発揮します。
●六甲式
国総研資料 第 204 号
参考:地震による斜面崩壊危険度評価判別式「六甲式」の改良と実時間運用
さらに一歩進んだリスクマップも公開されています。国内では崩壊データが整備されていませんので、土砂災害データが利用されていたり、民家の有無も考慮されたうえでの評価がなされています。
●土砂災害発生確率マップ(案)
国総研資料 第 1120 号
●ハザードマップポータル
ハザードマップポータルサイト
●キキクル
気象庁 | キキクル(危険度分布)
現状、機械学習を導入するだけで良いマップを作ることができるとは考えていません。おそらく、よく検討された六甲式や土砂災害確率マップの方が実態に近い結果を得られると思います。
将来、過去の崩壊データが整備される、あるいはリアルタイムで整備されるしくみが整い、人の手に負えなくなる量が毎年加えられる、というようなことになるかもしれません。そのような場合に、重回帰に代わってDNNを使う、適中率と捕捉率の同時向上=F1マクロを評価指標としてトレーニングする、などという取り換えが可能となり、良質なマップができるようになるのでしょう。
国内では、機械学習による LSM 作成を試しながらも、データ収集・提供の仕組みを整える必要があるのでしょう。